Deep Learning A to Z - ANN(4)
1. Compile ANN - keras
- Sequencial과 Dense로 제작된 ANN을 학습시킨다(compile)
2. 로직
import keras
from keras.models import Sequential
from keras.layers import Dense
classifier = Sequential()
classifier.add(Dense(units = 6, activation='relu', kernel_initializer='uniform', input_shape=(11,)))
classifier.add(Dense(units = 6, activation='relu', kernel_initializer='uniform'))
classifier.add(Dense(units = 1, activation='sigmoid', kernel_initializer='uniform'))
- Input layer - 1개 / Hidden layer - 2개 / Output layer - 1개 로 구성된 classifier NN을 준비한다.
- 준비된 NN을 compile 한다.
classifier.compile(optimizer = 'adam',loss = 'binary_crossentropy', metrics = ['accuracy'] )
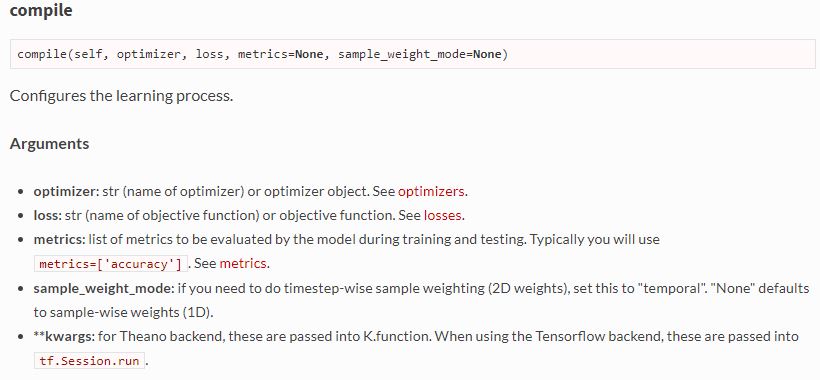
- Sequencial.compile 함수는 NN을 주어진 옵션으로 컴파일한다.
- optimizer : 예제에서 만든 NN모델에 맞는 optimizer 를 선택한다. SGD알고리즘의 optimizer는 adam 으로 논문화 되어있다.
- loss : loss function 은 cost function 과 유사하다. 즉, 실제 값과 측정 값의 차이를 보여주는 function .
- metrics : 실제 화면상 출력되는 결과를 표현한다.
classifier.compile(optimizer = 'adam',loss = 'binary_crossentropy', metrics = ['accuracy'] )
classifier.fit(X_train, y_train, batch_size=10, epochs=100)
- compile까지 된 NN 모델에 직접 데이터를 넣어 학습시키는 단계이다.
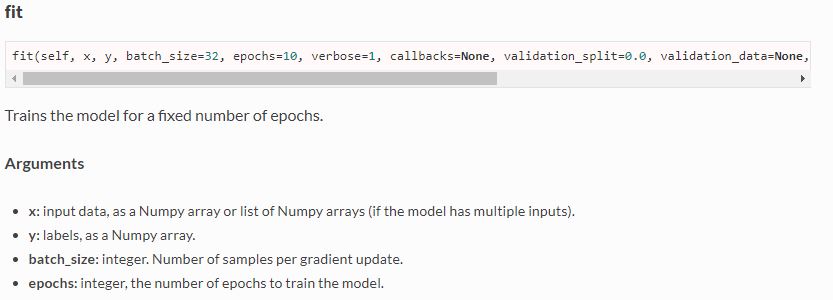
- Sequencial.fit 을 통해 미리정의한 dataset을 NN을 통과시키며 학습시킨다.
- X : 학습할 데이터
- Y : 결과값
- batch_size = 한번에 gradient(slope) 업데이트[처리] 할 데이터 샘플의 크기
- epochs = batchsize를 몇번 학습시킬 것인지 결정. -> 전체 모델을 batch_size로 나누고 한 batch를 epoch번 반복한다.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('Churn_Modelling.csv')
X = dataset.iloc[:, 3: 13].values
y = dataset.iloc[:, 13].values
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X_1 = LabelEncoder()
X[:, 1] = labelencoder_X_1.fit_transform(X[:, 1])
labelencoder_X_2 = LabelEncoder()
X[:, 2] = labelencoder_X_2.fit_transform(X[:, 2])
onehotencoder = OneHotEncoder(categorical_features = [1])
X = onehotencoder.fit_transform(X).toarray()
X = X[:, 1:]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
import keras
from keras.models import Sequential
from keras.layers import Dense
classifier = Sequential()
classifier.add(Dense(units = 6, activation='relu', kernel_initializer='uniform', input_shape=(11,)))
classifier.add(Dense(units = 6, activation='relu', kernel_initializer='uniform'))
classifier.add(Dense(units = 1, activation='sigmoid', kernel_initializer='uniform'))
classifier.compile(optimizer = 'adam',loss = 'binary_crossentropy', metrics = ['accuracy'] )
classifier.fit(X_train, y_train, batch_size=10, epochs=100)
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5)
"""
Geo : France
Credit : 600
Gender : Male
Age : 40
Tenure :3
Balance : 60000
NoP : 2
Card : 1
Is Ac : 1
Est.Sal : 50000
"""
new_prediction = classifier.predict(sc.transform(np.array([[0.0, 0, 600, 1, 40, 3, 60000, 2, 1, 1, 50000]])))
new_prediction = (new_prediction > 0.5)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
- y_pred = 학습된 NN에 대한 x_test 정확도 결과
- binary result 비교 시 사용되는 confusion_matrix를 통해 결과값을 조회한다.
- (0,0) / (1,1) 셀이 정확이 예측된 경우이며, 이를 통해 이 모델의 정확도를 구할 수 있다.
- 이번 모델을 아주 기초적이 케이스이며, 향후 복잡한 케이스 혹은 더 높은 정확도를 위해서 parameter tunning 등을 통해 정확도를 올릴 수 있다.